
Written by Antonis Markou, Machine Learning Engineer, Medoid AI
Can you just take a recommendation algorithm, like collaborative filtering, out of the box and apply it in your business? The short answer is: not in a real-world setting. Imagine running a website whose primary goal is recommending news articles according to user preferences. New articles are added non-stop and you may want to provide recommendations to these newly added articles too. This is a valid demand considering the fact that news, like vegetables, are better to be consumed when they are fresh. However, this is not possible in collaborative filtering without constant and costly retraining. This is the single most important challenge of a collaborative filtering algorithm: handling new items.
So, how can we handle cases like these when collaborative filtering is suddenly useless? Well, it depends (what a convenient answer!). In this article, we will create a plug-and-play module, which sits on top of our recommendation engine and handles this problem.
Collaborative Filtering & User Feedback
Collaborative filtering is a classic and very widely used recommender algorithm that automatically estimates the probability of a user A interacting with an item B. To provide recommendations it uses historical data of user feedback on the available items collection. There are basically two types of user feedback, explicit and implicit.
Explicit feedback is considered to be a kind of direct information about the user’s preferences. A typical example is when a user rates an item. In this case, the user may express a positive or negative opinion about a specific item. The algorithm will then try to “guess” the rating the user would give to items he has never interacted with.
On the contrary, implicit feedback means that any information on whether a user likes a specific item comes indirectly through his interactions. For example, when a user actually buys a recommended item from an e-shop this represents positive, indirect, feedback from the algorithm’s perspective.
Implicit feedback comes with a great benefit but also a challenge. You can immediately use all past user interactions and bootstrap your brand new recommendation system with them, without needing to enter a period of data collection expecting explicit feedback from your users. However, the benefit of using implicit feedback comes at a cost. By its very definition, implicit feedback can not express negative user interactions, thus treating items that had no user interactions (for example the user did not read an article or didn’t listen to a song) as like the user disliked them, even though he may have never been aware of their existence.
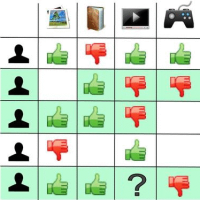
Utility Matrix
Now, imagine that multiple interactions between users and available items are collected in an implicit way. We may then construct a 2-dimensional matrix (called Utility Matrix) having as many rows as the number of users (being present in the collected data) and having as many columns as the available items. This matrix will be filled either with zeros — representing that a user didn’t interact with an item — or some value greater than zero meaning that a user indeed interacted with an item. The value may reflect the number of interactions or just be 1 if we only care about the fact that an interaction occurred.
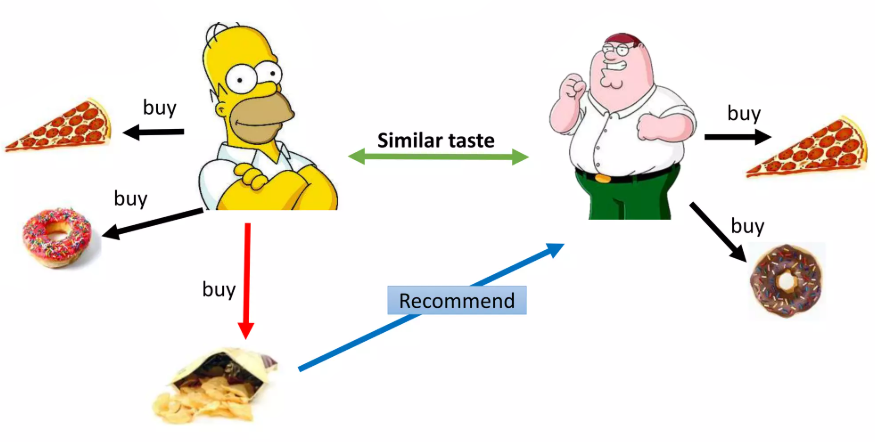
The key intuition behind collaborative filtering is that the expected recommendations are actually “corrections” of this utility matrix. For example, let’s define “similar users” as the users whose interactions look very similar (similar utility matrix rows). Now suppose that a bunch of similar users, all except for one, have interacted with a specific item. Obviously, the first thing to come to our mind is that maybe that single user was unaware of that item. For that reason and in layman terms we could say that the algorithm will “correct” the zero value of that interaction into a higher one by recommending that item to the specific user.
Matrix Factorization & Items Similarity
Having already described the core idea behind collaborative filtering, we can discuss some technical approaches for the algorithm implementation. Matrix factorization, for example, is a widely used approach and is the one we will use in this case. As the name implies, matrix factorization tries to model the reconstructed matrix (the output of collaborative filtering) as the dot product of two smaller matrices. The first matrix refers to the users and has as many rows as the existing users and the second one refers to the existing items. The number of columns for both matrices is a user-defined parameter (user here refers to the person who implements the algorithm) and represents the number of “latent” features the users and items have.
Normally, in the absence of matrix factorization, we would just find the row of the user and the column of the item we care about and just retrieve the corresponding value (obviously assuming that the matrix was reconstructed using a different approach). But in matrix factorization’s case, if we would like to retrieve a guess for a specific user-item pair we just have to calculate the dot product between the row of the corresponding user with the row of the corresponding item. Fair simple right? These latent features have no physical meaning and they are just a proxy for calculating the estimation of whether a user will be likely to interact with a specific item or not.
However, the cool part about these feature vectors (i.e. latent features) is that items (or even users) considered to be similar, such as two t-shirts of the same brand having the same style but different colors, will have their feature vectors close as well. This can be easily verified through the use of the appropriate similarity metrics (e.g. cosine similarity or euclidean distance). In fact, this is how an abstract concept, such as similarity, maybe quantified when expressing it through a vector space. When two items are considered to be similar, then the distance between their vectors will result in a very low number (alternatively the cosine similarity will be close to 1).

When trying to implement a recommendation system, we supposedly have information about the interactions/ratings of several users against several items. Using this data the algorithm will try to estimate which users-items pairs, that have never been observed, are likely to occur. Using matrix factorization, we may retrieve such information by constructing two separate matrices for users and items and apply simple matrix operations to discover similar users or similar items.
Theory vs Reality
In general, collaborative filtering is guaranteed to produce very good results. And how wouldn’t it be when Netflix, Amazon, and Spotify are making serious use of it? However, one key difference that separates expectations from reality is that collaborative filtering isn’t plug n play (like most ML algorithms). In fact, special care and effort should be made to build the utility matrix (the matrix containing the information of users-items interactions) and this will drive the design and architecture of the system to a large extent.
But what exactly is so challenging about defining a real-world Utility Matrix? Well, recall that the algorithm will just adjust the users-items matrix for making the data more consistent with each other (we mentioned earlier an example about similar users), calculating missing interactions in a feasible way. These missing interactions refer to either user has interacted with other items or items having received interactions from other users. However, the algorithm is unable to evaluate possible interactions involving new users and/or new items, as this is mostly the case in real-world problems, where the pool of users and items is constantly being updated.


Handling New Items
We will consider two cases here, one challenging case where we want to evaluate and subsequently recommend new items that have no interactions yet, and the simpler case of delaying evaluation until you get data.
“We can wait until we get some data!”
Depending on the business requirements at hand, it may not be critical to delay the evaluation of new items until a number of users have interacted with them.
We may think “OK, if new items are added and some users have already interacted with them, then let’s just update the utility matrix”. But reality suggests differently. Considering a large number of items and users (thousands to millions for each category) being present in the dataset, millions of heavy computational calculations need to take place during training. Even with distributed data engines like Spark, training often (for example in a daily routine) translates into using excessive amounts of resources and this is usually not feasible at all.
Several approaches have been proposed to incrementally train a collaborative filtering algorithm by using only the new interactions (not updating the whole matrix by performing a full training) but even then, this would result in an approximate model, which, in turn, usually means lower model performance.
“We need to evaluate new items immediately and produce recommendations for them”
This case, unlike the previous one, lets us assume that no data (interactions) for the new items exist at all, and that’s why it is considered to be a more difficult case. But if it was something easy then we wouldn’t bother writing this article right? To handle this case we will describe the Indirect Recommendations methodology.
The idea behind Indirect Recommendations
The core idea we will discuss here is to exploit similarities between the new “unknown” items and the already known items for which we already have interaction data. More precisely, if the algorithm predicts that there is a high/low probability for a specific user to interact with a specific item then it is very possible that this applies for any other similar item too.
To elaborate further on this idea, a reasonable example would be the following. Assuming that user A has a high probability (due to the algorithm’s result) of interacting with an article having the title “Whales will be extinct in the future”, then it makes sense that he will also like another article, which is unknown to the algorithm at the moment, about how lions’ lives are put in danger due to humans’ intervention. Accordingly, if the algorithm thinks that the same user is not very likely to interact with an article discussing new car models of 2020, then we may reasonably think that an article about the new Tesla model, will not draw his attention either.
Now, recall what we mentioned earlier about how matrix factorization produces some latent features which are suitable for calculating similarities between known items (and between known users as well). When the algorithm is prompted to give the top K recommended items for user A then we wouldn’t be surprised if the similarities between these recommended items are very high when these are calculated in the feature space. In the example above (the articles about whales and lions), we also evaluated similarities between items, but this time we used another kind of features. Besides, latent features for this item do not exist due to the lack of interactions.
Content-based features
Since latent features can not be calculated for items missing from the utility matrix (no interaction items), we may build features that characterize items and allow generalization among them. But what are these features? Recall the example regarding the whales and lions. Both of these articles talk about animals and threats. We, as humans, are able to derive similarities like this because we know that whales and lions are both considered to be animals. More specifically we exploited features that are item-specific. We have naturally categorized both of the articles in the animals’ category.
These kinds of features are called “content-based” features because they describe the content of each item. Unfortunately, the collaborative filtering algorithm is not able to deduce that by itself. The only thing that matters for the algorithm is the interactions between users and items and, thus, the article about whales is just an item with a corresponding numerical ID. If only another way existed for modeling these features, then we could make use of it in combination with collaborative filtering. Fortunately, there are plenty of methods depending on the situation.
In order to represent items using content-based features, we could use the so-called categorical features. In such cases, we may create hierarchies of categorical features. Assuming a clothing dataset, these features could be the string description of the brand-gender-collection-color-size of each item. In other cases, we could use numerical features. Let’s say that you are dealing with trading card games through an online marketplace. Assuming that your cards are described by various attributes, these can be used as numerical features. Some regular attributes are the following: Attack, Defense, HP (hit points), etc. Depending on the play-style /deck build of each customer (aggressive, passive, defensive, etc.), which in turn is reflected by his past orders, you may recommend similar cards. For example, a customer using an aggressive play style will probably be more interested in trading cards having high Attack statistics.
Indirect Recommendations Recap
If we were to describe the aforementioned ideas in a nutshell then we could say that available items are divided in two categories; items for which information about interactions exists and brand new items accompanied with no such kind of information. When it is needed to provide a prediction for a specific item, then if this item belongs in the former category, the prediction is directly provided by the algorithm. We arbitrarily call that “exact matching” because the algorithm already knows information about that item. On the other hand, if the item belongs in the latter category then we provide the prediction of the most similar item for which the algorithm may directly provide a prediction value. Due to the fact that this prediction is obtained indirectly (it wasn’t produced for that specific item), we call that an “Indirect Recommendation”.

Use Case: Indirect Recommendations & Categorical Content-Based Features – Indirect Recommendations difficulties
Now that we have a more clear understanding of how we could exploit similarities between items in order to increase items coverage, we could sum up with a demonstrative example.
Let’s assume that our items are described by categorical features, which take values from a hierarchy, and that new items are constantly added and thereby offered to users. For our purpose, the case of news articles seems to be a fair choice. The articles could be organized using categories, (for example animals, politics, etc) and subcategories (for example exotic, middle-east, etc) as well as some additional tag words. By gathering all available data about user-items interactions we can train our algorithm. Having done that, we are able to provide recommendations to our users but these recommendations will be limited in the already known items’ pool.
Now assume that new articles are constantly added (in a very similar manner to Wikipedia) but, due to their vast amount, most of them are not likely to be spotted by the users and subsequently receive interactions. For handling these cases, using “Indirect Recommendations”, we need to represent these items using content-based features. Assuming that items being in the same category-subcategory and having similar tag words are indeed similar, we want their content-based feature vectors to be close enough in the feature space. In such cases, a usual approach is to use tf-idf with character n-grams. The explanation of this method is out of this article’s scope so in case it sounds unfamiliar please refer to this article.
Using the n-grams tf-idf representation we can provide the values of category-subcategory and tag words regarding our item and receive a feature vector representing the content of this item. Our aim is to find the most similar items for our query item through this representation. Again, most implementations provide the capability of returning the most similar items (in category-subcategory level) given the item of interest along with the similarity level.
Let’s assume that the new item belongs to the martial arts category and tae kwon do subcategory having two tag words: “2020” and “champions”. By providing this item in the tf-idf related implementation, we expect results like “martial arts – tae kwon do – 2020 similarity: 0.99”, “martial arts – tae kwon do ITF – tournament similarity: 0.95”, “martial arts – tae kwon do WTF – gyms similarity: 0.95″, ” Korean martial arts – tae kwon do – traditional similarity: 0.87″, “martial arts – BJJ – top athletes similarity: 0.5”. Now we may just pick the top similar item from the already known items’ list or combine the predictions of many top items and average them.
An important thing to mention here is that this prediction was created for the known items exclusively. For that reason, we should take into account the level of similarity. One simple way to deal with it is to multiply the prediction with the similarity. For the case of two completely similar items, we are confident of providing the same prediction. On the other hand, for two moderately similar items (for example similarity equal to 0.7) we should decrease the prediction a little bit since we are not that confident. However, since several items could be similar to the one we want to evaluate, and even more sophisticated approach would be to perform the same weighting on predictions of multiple items and finally average these results.
Please note that it was up to us to decide what information we could use as our content-based features (category, subcategory, and tag words). We could have chosen to use the article’s title instead, which is reasonable as well. In fact, both approaches should be tested for choosing the most appropriate depending on their performance.
I hope you enjoyed this post and most importantly that you got a sense of how to deal with the significant real-world challenge of implementing a recommendation engine.
