
Written by Christina Chrysouli, Lead Data Scientist, Medoid AI and Antonis Markou, Machine Learning Engineer, Medoid AI

Topics we will cover in this blog:
- Money Laundering Today
- Machine Learning in the new AML Landascape
- Challenges of Traditional AML Solutions
- Advantages of Machine Learning Solutions in AML
- Data for Machine Learning Solutions in AML
- Limitations of Machine Learning Solutions
- Medoid AI – What do we offer
Money Laundering Today
As technology advances, so do money laundering techniques. This rapid growth provides new and more tools to money launderers. It allows them to transfer and conceal money around the globe easier and faster than ever before. Blockchain, for example, is a technology advance that has disrupted the financial landscape recently. Money launderers have exploited the new hype of cryptocurrencies to facilitate their needs. Cryptocurrencies have become one of the most favored means for criminals to collect, store and launder money. An analysis found that, in 2019, criminals laundered a total amount of around $2.8 billion, only in Bitcoin, through cryptocurrency exchanges.
Regulators are forced to adapt to these new-age transaction methods, by introducing laws and regulations. They include new forms of money laundering to keep pace with the ever-advancing technology. In the 6th AML Directive alone, 6 new predicate offenses have been added, indicative of how fast this area is moving.
“The resourcefulness and technical expertise of criminals have risen to high levels: fighting financial crime is more difficult than ever.”
The resourcefulness and technical expertise of criminals have risen to high levels; fighting financial crime (including Financing of Terrorism CFT) is more difficult than ever. More sophisticated counter-measures are required, with current machine learning techniques being the weapon of choice. Regulators have also identified the need of adopting machine learning techniques. The European Banking Authority (EBA) published a report, in 2020, regarding key considerations in the development, implementation, and adoption of Big Data and Advanced Analytics techniques, such as machine learning. In the online gaming sector, there are also examples of authorities embracing the adoption of machine learning algorithms (MGA, UKGC).
In the next sections, we will first briefly introduce some basic concepts needed for better understanding machine learning. Then, we will focus on the disadvantages of legacy AML solutions and how they are affecting businesses. We will also point out how a machine learning automated solution can be the core component of your anti-money laundering efforts. We will also discuss in depth the limitations of machine learning solutions. Last, but not least, we will emphasize how an automated machine learning solution on anti-money laundering can empower any business.
Machine Learning in the new AML landscape
If we were to describe machine learning simply, then that would be the process of training a computer to carry out human tasks which usually require intelligence and critical thinking. This process requires providing data relevant to the task. There are two major approaches to machine learning (see also image 1):
- Supervised Learning: The human teaches the computer to associate sample data characteristics to predefined output targets. An example could be answering the question: “Which attribute values were associated with cases of suspicious activity?” The computer is then able to predict whether a new case falls into a given category. Or, in AML terms, whether this is a suspicious case or not. It could even predict a number, for example the number of future deposits. The prediction process happens in the same manner as a human would do, in fact, many times even better.
- Unsupervised Learning: The human lets the computer figure out insights and patterns in the data which would otherwise be invisible to the human eye. Imagine, for example, letting a computer decide about the grouping of customers in risk levels, based on some of their characteristics (customer segmentation).
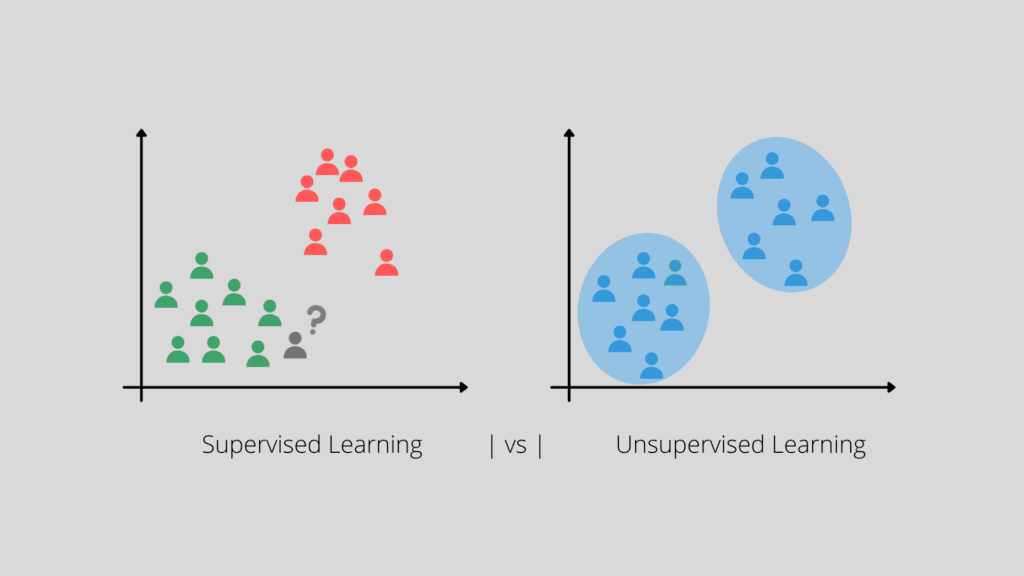
Applications of Machine Learning in AML
Nowadays, more and more Financial Institutions (FIs), online gaming operators, and other obliged entities adopt machine learning techniques to optimize or improve their services. Let’s summarize some of the most promising applications of AML, that could benefit from machine learning:
- Transaction monitoring
- Generate payment screening alerts
- Customer monitoring – risk profile update
- Customer segmentation, that is, identifying groups of similar customers
- Enrich customers’ risk profiles by incorporating information from external sources (sanctions, negative news etc.)
- Automate reports generation
- Automate routine tasks such as customer’s identification through documents verification
- Linking different customers/transactions through indirect interactions
- Automated analysis for identifying which attributes are more important for predicting Money Laundering
Business-customized Machine Learning Solutions
Every business has its own needs, depending on how large or small they are and if they focus on a niche market or not. Also, it depends on their financial resources and their business legal structure. Moreover, while every transaction carries a risk of being associated with money laundering, there are industries where the risk is significantly higher. Examples of such high-risk industries include financial institutions, payment processing companies, and companies involved in real estate sales.
Depending on all these factors, the needs of every company on anti-money laundering processes are quite different, even unique. For example, a small real estate firm, with a small compliance team (or even no compliance-specific team) is probably more interested in acquiring an automated AML solution. This way, small firms will be able to handle all the suspicious cases, without the need of hiring more people. On the other hand, a larger company would probably acquire such a solution to scale its operations more efficiently.
Challenges of traditional AML Solutions
With millions of customers and billions of transactions every day, most of the obliged entities have developed manual transaction monitoring systems. This way, they get alerts for certain customers, abnormal customer activities, and potential criminal activity. This monitoring system is traditionally based on predefined rules, to convert AML business scenarios into computer-based algorithms. Manually handling every single alert is a complex and time-consuming process for every compliance department.
Although rule-based systems are a quite common practice nowadays, their mechanisms used for detecting financial crime have proven flawed and inefficient most of the time. This becomes evident when viewing the fines imposed on FIs and other obliged entities only in 2020, with the amount reaching $10.6 billion.
Let’s review the reasons why legacy rule-based solutions are prone to fail at handling the constantly increasing needs of businesses on AML laws and regulations.
Insufficient number of AML compliance officers
There are two reasons for the increased demand for AML:
- the huge number of new accounts created every day (bank accounts, online gaming accounts, etc)
- the rapid adoption of online payments and digital wallets in people’s everyday life
Moreover, the COVID-19 pandemic has accelerated both the number of customers who started using digital accounts for their everyday transactions and the online transaction volumes. But is every compliance team sufficient to handle the demand?
“Legacy rule-based systems are often highly inefficient, mainly due to the fact that they generate lots of unnecessary alerts.”
Legacy rule-based systems are often highly inefficient, mainly because they generate lots of unnecessary alerts. A significant number of compliance officers and analysts are then required to cover the laborious task of scrutinizing every transaction that the system produced an alert for. This manual work makes traditional solutions difficult to scale. Not being able to scale would probably lead to customers’ frustration and even disrupt the customer experience. Holding up or delaying payments unnecessarily due to increased workload is a rather bad customer experience.
Obliged entities need to adapt and improve their transaction monitoring procedures, to be able to handle the demand. This need directly translates to the necessity of altering and/or enhancing their Know Your Customer (KYC) processes. Every new onboarding also includes many other risk assessment processes which add to the workload:
- Politically Exposed Person (PEP)
- Ultimate Beneficial Owner (UBO)
- Customer Due Diligence (CDD) data collection
- Adverse Media checks
- Sanctions screening.
According to a study, one-third of financial institutions have lost customers due to inefficient or slow onboarding.
Moreover, soon after the pandemic outbreak, it became evident that the customers’ transactional behavior had changed. A lot of customers, that didn’t use to make any online transactions even for shopping the essentials, were “forced” to do so due to closed shops and fear of getting infected by the virus. This behavioral shift means that old patterns of money laundering might not be valid anymore, leading to the need for a screening process shift.
False Positive Cases
Legacy transaction monitoring systems generate alerts whenever they detect suspicious activity, based on a threshold. However, every system has errors, thus, not every alert indicates money laundering.
In simple terms, a false positive case is a case where the system gives an alert pointing out that something suspicious happened which, usually after a long meticulous investigation, results in a non-suspicious case. This is exactly the case with legacy AML systems: they produce a great number of alerts that are later proven to be “false alarms”.
False-positive cases concern up to 99% of the alerts produced by rule-based systems. The problem gets even worse if consider that rule-based systems do not have a fine-grained scale. That scale is to evaluate which transaction/customer is potentially more suspicious than another (usually there are just a few ranking levels).
Someone could say: “ok then, let’s move the threshold and get fewer false positives”. Companies sometimes adopt this solution to reduce the number of alerts. Although it might seem that it solves the problem, in reality, it generates another: false negatives. False negatives refer to actual suspicious cases that the system is not able to retrieve. Just moving the threshold simply decreases one error at the expense of the other (see image 2).
The price that companies must pay, due to false positives, is not only wasted resources like investigation time and money. They also affect customer experience: no customer wants to be treated as if they were criminals when they are not.
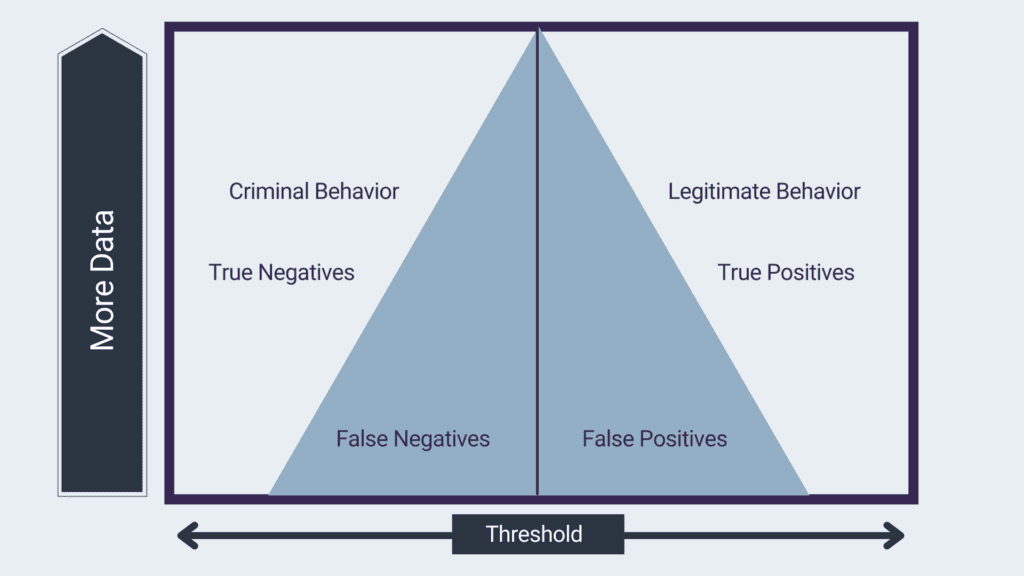
Weaknesses of rule-based systems
A significant drawback of the traditional rule-based systems is the rules themselves. Rules can be very narrow-viewed: what someone perceives as normal transactional behavior for a customer, another might consider as suspicious. In most legacy monitoring systems, in order not to miss any suspicious behavior, businesses prefer to have more loose rules. This comes with the cost of getting too many unnecessary alerts.
Rules are too strict: there is usually a “hard” threshold when a transaction is considered to be suspicious, and an alert is generated. In many cases, the difference between a transaction related to money laundering and a legitimate transaction is really small. A threshold is usually unable to detect subtle differences, leading to missing actual cases while getting alerts for non-suspicious ones.
The maintenance of a rule-based system is a very time-intensive task in an ever-changing laws and regulations world. All entities are obliged to modify and update their system rules, to be able to keep up with the laws.
Mistakes by Compliance Team
The human factor, as precious in so many processes, can also become a major disadvantage of these legacy systems. Due to different styles of case processing among compliance officers, there is a great possibility that processing a case will result in a different outcome among different officers: several officers would conclude that a client has suspicious activity, while others won’t identify any fraudulent activity (image 3). This inconsistency often requires a whole team of compliance officers to decide on a suspicious case, which is not time efficient.
Transaction monitoring processes need to evolve in time for two reasons. The first one, to be following the laws and regulations. The second one, to capture the ever-changing techniques that money launderers use. Training and re-training employees on AML is a crucial and time consuming and expensive process. Even with the best training, errors are inevitable when processes change so often, and officers need to make a plethora of subjective judgments.
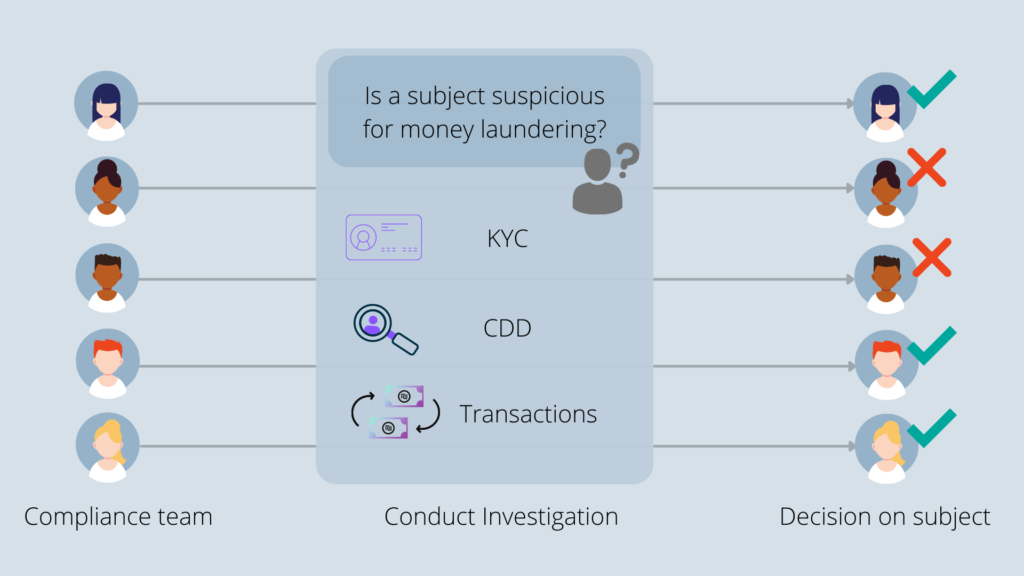
Advantages of Machine Learning Solutions in AML
The rapidly changing landscape of AML regulations, in combination with the growing number of transactions and customers, leaves almost no room for a traditional manual approach. Not only is the risk of fines fairly high, but the whole process is resource-demanding and time-consuming. After all, it is the regulators (e.g. in the Joint Statement on Innovative Efforts to Combat Money Laundering) who push in the direction of automated solutions because AML has become more complex than ever. Fortunately, machine learning-based AML solutions may carry out all the necessary tasks automatically and efficiently.
Let’s see why these solutions are promising and what they have to offer.

Enhanced Transaction Monitoring
Through the use of historical data, a machine learning solution can learn and identify complex patterns in transactions. These patterns, such as structuring/smurfing, are rather difficult to reveal by human inspection. Moreover, while Money Laundering schemes change over time, the system can adapt to the new reality. By incorporating any new information automatically, they can identify almost any new transactional pattern.
Usually, only a tiny portion of the transactions are related to money laundering: the vast majority of the customers have legitimate transactions. To that end, the machine learning system can identify whether a behavior is normal or not. Any transactional behavior deviating from the normal behavior is considered to be an anomaly and flagged as suspicious (outlier detection algorithms). Such kinds of systems perform with relative accuracy, achieving a dramatic reduction in false positives and false negatives compared to rule-based systems. To have a sense of actual performance figures, ask for our detailed client case studies. Numerous parameters can contribute to the system’s customization, by either focusing on the reduction of false positives or false negatives.
By considering more than a single data source, we may achieve high efficiency of the system. This is performed by taking advantage of a variety of different signals, through a process called data augmentation. Apart from the transactional information itself, the system may cross-check other information too. For example, customer-profile data (e.g. CRM information) may allow the system to produce more accurate risk scores than rule-based systems.
There is no doubt that this automated and highly accurate process could allow analysts to focus only on cases that matter the most (suspicious cases). This is possible thanks to the ability to process a vast number of transactions concurrently (big data technologies). Moreover, in that way, a business may allocate human resources elsewhere, reducing the workload and, therefore, the overall compliance costs.
“Another advantage of an AI AML system is the prioritization of alerts, which allows the compliance officers to focus on the most urgent alerts first.”
Another advantage of an AI AML system is the prioritization of alerts, which allows the compliance officers to focus on the most urgent alerts first. We could also augment these alerts with extra context, helping in that way the analysts for better decision making.
Detecting Behavior in Transaction Monitoring
Similar to transaction monitoring, we can make use of advanced AI techniques to model each customer’s transactional behavior. Based on that modeling, the AI system can detect behavioral changes in customers’ profiles. Such kinds of changes may indicate, for example, that a criminal user, other than the one holding the customer’s account, operates through this customer (account takeover). Of course, not all customers share the same behavior. For that reason, a single transaction may be regular for some of them, while for others should raise suspicions. AI systems are very effective in distinguishing risks according to a customer’s regular behavior. Additionally, they can spot suspicious anomalies otherwise difficult to detect even by a human expert.
Another important aspect of an AI AML system is the ability to group similar entities, based on some characteristics through cluster analysis. These entities could be the customers themselves. During this process, high-risk customers will be grouped, given that the appropriate characteristics are chosen. When we have that grouping, experts need to thoroughly check all customers that fall into this high-risk group. This happens regardless of whether they were older customers, who were not previously identified as high risk, or new ones. The grouping can provide an easy, fast, and automated way to identify high-risk customers with high precision.
Effective AML Link Analysis
As the number of data increases, it is fairly difficult for the compliance teams to find connections between entities (e.g transactions or customers). You can try to picture the connections between all clients that are somehow linked. The result would be something like a spider web. Chaotic, right?. Trying to manually research every connection is like looking for a needle in a haystack. This endeavor may take years to complete for every possible connection. Fortunately, when using appropriate machine learning techniques & metrics (for example graph analytics) it is relatively easy to spot linkages in this vast volume of valuable information.
Automated link analysis can reveal connections between different transactions, which may have occurred anywhere, uncovering hidden patterns. Implicit relationships between different customers are also possible to unveil. For example, some customers may act as a hub in a transactional network. Others may act as a bridge between customers. When combining information of high-risk profiles, it is just a matter of time to backtrack the route of the illegal activity.
Simplifying Screening Processes – KYC
Undoubtedly, AI-based solutions may offer extremely high automation in screening processes, and more importantly KYC area. Time-consuming manual routine tasks are just a matter of seconds to complete by an automated machine learning solution, which also improves the user experience.
According to our experience, the first and most important task that needs automation is the process of identity verification. This includes the verification of digital documents and personal information. Through the use of powerful image recognition algorithms, it is possible to identify the structure of a document (object detection/recognition). Or even extract the information from each field a document contains (optical character recognition). Using the same technology it is easy to check the authenticity of a scanned document provided by a customer (fake image detection).
The task of checking whether a customer’s identity matches an external risk database entry could benefit a lot from machine learning. When a human needs to manually perform it, it can be quite difficult and time-consuming, since there are two different data sources to check. Luckily, by using Natural Language Processing (NLP) algorithms, it is fairly easy to cross-check contextual information in different data sources.
Apart from risk databases, there are numerous other important data sources to take into account when constructing a customer’s risk profile. Examples include data sources such as news articles, social networks, etc., which may provide additional insights about the customer’s background. Again, through the use of NLP algorithms, the aim is to combine these different sources and uncover any hidden connections. The most common example is checking whether a customer is related to a PEP situation.
Data for Machine Learning Solutions in AML
When designing and implementing an AI-based AML solution, one of the most crucial components is the data that will be fed into the system. This data is the backbone of every machine learning solution because it will determine the algorithm’s ability to learn. But what do we need to pay attention to?
What data does an AI-based AML system need to operate?
“Transactional data, customer profile information, and behavioral information which are important for the officer are also crucial for the system.”
Now that we might have your attention about the importance of a machine learning automated system, let’s see what data it needs to operate. The answer is simple. Any data that a compliance officer goes through, to perform a specific task or investigate a suspicious case. Such data, like transactional data, customer profile information, and behavioral information which are important for the officer are also crucial for the system.
There is a rule of thumb in machine learning that states “the more data, the best”. This translates into:
- The bigger the data volume, the best
- The bigger the data diversity, the best
Data volume is important since, when providing a lot of data to the system, it is more probable to detect more patterns. In other words, the system will acquire a more complete overview of the patterns and interactions being present in the data. Let us assume having an AI system that scores a specific transaction in terms of how risky it is. Then, it will produce better results when we have previously provided adequate data. The aim is to include all kinds of customers’ behaviors, as well as a big portion of transactional history. For example, non-commercial customers who are engaged in high-frequency transactions might be related to high risk. The provided data must be as comprehensive as possible if we want to detect any existing pattern.
Data diversity refers to providing data from as many as possible sources (external sources included as well). The available information is not always enough to conclude. For example, a single transaction’s characteristics may indicate a high risk for a given customer, whereas it may be a regular transaction for another. So, using only the transactional data itself is inadequate for deciding. For that reason, it is essential to combine as much diverse information as possible. Eventually, the ML-based system is clever enough to decide which information is useful or not.
Data quality in AML
One of the biggest challenges when implementing a machine learning project is the quality of the available data. Building an AI-based automated AML solution is not an exception. There is a saying stating “garbage in, garbage out”. In our case, this translates to the final result is going to be as good as the data fed to the system.
There are four common problems of low-quality data:
- Missing data
- Outdated data
- Mislabeled data
- Contradicting data
Missing data
Most machine learning algorithms can only operate when all the necessary entity’s characteristics are provided. Before the algorithm is trained to carry out a specific task, we have to make sure of two things. First, to define the entity under consideration (either a customer or a transaction) and, second, which characteristics to use. As long as these two prerequisites are defined, the system will operate based on them.
For example, let us suppose that the entity is the customer and the characteristics that the algorithm will use, including payment information. When we invoke the system to assess a customer with missing payment information, the task is more likely to fail. Note that this limitation applies only to characteristics that we, as humans, indicated as required during the system design. There are times when a character is important for the performance of a required task. However, if this characteristic has missing values in most of the cases, this will negatively affect the algorithm’s ability to learn the task. Or even make it impossible to use.
Outdated data
Another issue that makes the system’s performance can significantly drop, is not using up-to-date data. Criminals keep on evolving their techniques and this is reflected in the data patterns. Low-risk behaviors change too and, thus, using outdated data may increase the false positives rate. Last but not least, any characteristic may obtain new values as time passes, for example when a new payment method is added. The algorithm needs to be fed with data covering all the potential values to make sure it operates smoothly.
Mislabeled data
The algorithm’s ability to learn is also associated with the “labels”, i.e. the category that each entity belongs to. In layman’s terms, labeling refers to annotating an entity for machine training purposes. For example, a customer may be suspicious of Money Laundering or not. In the end, the algorithm learns to associate the entities’ characteristics values with the labels. That means that the algorithm can separate one category (also called class) from the other. For that reason, it is crucial to provide data with as many correct labels as possible.
For the case of AML, this requirement is much more important. There is only a small amount of labels indicating money laundering, making them even more valuable. It is important to remove any mislabeled cases from the provided data. Otherwise, these mistakes might be propagated to the system’s output, meaning that the algorithm will inevitably misjudge similar cases.
Contradicting data
“Two or more customers have the exact same characteristics, but their risk levels are different.”
When training a machine learning algorithm, it is very important to have cases demonstrating a variety of different patterns. There exist cases, though, that two or more customers have the same characteristics, but their risk levels are different. This data contradiction usually implies that the algorithm needs more customer/transaction-related characteristics. Imagine for example two customers with the same demographic data who both deposit $10K. If we only feed the algorithm with these demographic data, the model won’t be able to differentiate between the two. But what if we feed the algorithm with data related to employment? Suppose that one of them has income through their job, while the other one does not. Feeding the system with this information would allow it to detect which one is suspicious and which one is not.
Limitations of Machine Learning Solutions
“Trust in AI is not built by endlessly reducing its failures but by understanding its processes and its limitations.”
Even though machine learning is nowadays capable of handling AML tasks efficiently and at scale, there are several limitations and challenges. These limitations may undermine the performance of the AI-based AML solution or even make it useless in some cases. A common challenge for any AI system is its actual adoption from business users. Even a single case of failure of the machine learning system can significantly undermine trust. Especially if there is no understanding of what caused the failure. It is important to build an AI culture for your team and be aware of all limitations and efforts still needed from the business side. Such an understanding will allow everyone to sign in to the process, minimize frustration or unexpected outcomes. Trust in AI is not built by endlessly reducing its failures but by understanding its processes and its limitations.
Data quality
“Actually, data quality is not a limitation: not being able to overcome bad quality is.”
The first and foremost limitation to mention is the quality of the data fueling the system. The performance of the final system will be as good as the data provided to it. Data quality is not a limitation: not being able to overcome bad quality is. As current algorithms don’t have a strategy to identify and overcome “bad data”, this burden falls on the shoulders of businesses to handle. Apart from that, every company interested in applying machine learning will need to put considerable effort, especially in the beginning. Such projects usually require appropriately preparing the data when it is not suitably organized, a quite demanding task.
Monitoring
Satisfying several KPI values and testing the system are two aspects to consider when adopting a machine learning solution in production. However, these alone are not enough to just let the system operate on its own. Such kinds of systems usually work under constant monitoring to avoid any critical issue from going unnoticed. These systems are not aiming at completely substituting the human factor, rather than operating in a supportive manner.
Explainability
Another drawback is that most machine learning algorithms act as black boxes. This means that most of the time, it is impossible for a human expert to interpret the decision of an AI-based system. Questions like “Why did the algorithm flag this particular transaction as risky?” are quite likely to remain unanswered. However, some algorithms may provide a naive explainability on which features they consider to be important overall.
Following the previous limitation, it is also important to note here that this lack of explainability collides with the demands of regulators. Each decision the compliance team makes and each result produced, should be based on comprehensive investigation and documented appropriately. If the compliance team is not able to document their decisions, it is rather difficult to come unnoticed by the regulators. Machines cannot be held accountable at the time of writing this! Since machine learning systems are usually quite complex, a risk management policy should be in place to anticipate all types of failure.
Computational Resources
It is evident that a machine learning AML solution may indirectly reduce the overall costs of the compliance program. This is a consequence of the automation it offers and the ability to process vast amounts of data. However, these perks don’t come for free. The process of (re) training and tuning machine learning algorithms usually requires a large number of computations. Data processing procedure, which is required when the algorithm is invoked to perform a task, is also a computationally intensive task. As the amount of data grows, so do the requirements for computational resources. In fact, special consideration should be given to evaluating whether the cost of maintaining such resources is feasible or not.
Medoid AI – What do we offer
“Machine learning solutions in AML will not eliminate the need for human compliance teams, but rather empower them.”
Let us start with a statement: machine learning solutions in AML will not eliminate the need for human compliance teams, but rather empower them, help them reach conclusions faster, more efficiently, and easier by giving them access to new tools. Here is a summary of what Medoid AI offers, a solution tailored to your needs.
- Feature engineering
Feature engineering is the process of converting raw data into informative characteristics data that can help a machine learning system differentiate cases. Medoid AI has a lot of experience in building features related to anti-money laundering. We have been working closely with Compliance professionals, successfully translating complex business criteria into AI meaningful features.
Imagine what a compliance officer would do to decide if someone has suspicious activity. They would look for clues in their available data. First, they would look for some demographic data, such as age and nationality. But this data alone is not even close to enough to decide if an activity is suspicious or not. Then they would need to search the news, check their background, whether they are PEP, something irregular going on? Still not enough clues though. They keep going, they would need to go deeper, looking through all their transactions. First the latest ones. Then across different time horizons, to capture a holistic view of their transactional activities, look for a pattern. It is already starting to be a time-intensive process.
In fact, the task of collecting data takes up over half of an officer’s or analyst’s time. Now envision not only having all this data collected and transformed but also converted into features that will help the algorithm decide automatically. This is our work.
- Prioritization of riskier customers/transactions
Legacy transaction monitoring systems usually have a small number of alert levels. Even at the highest level though, this corresponds to hundreds if not thousands of alerts every day. Our solutions come with a handy feature that allows you to view customers or transactions ordered by their probability of being suspected of money laundering. This way, the compliance team can focus on the highest risk cases, saving time and working more efficiently.
- Explainable results
Imagine not only having an ordering of customers based on the risk they pose to the company, but also having a small summary of why each customer has been identified as a possible money launderer! In Medoid AI, we focus on explaining why a machine learning algorithm “believes” that a customer or transaction is a money laundering case. We can expose the reasons (=meaningful features) that led to the algorithm’s decision. This allows officers to further investigate these cases on their own, also offering useful insights into transactions and customer patterns.
- Suspicious Activity Report and Currency Transaction Report
In an independent audit, the examination of a company’s anti-money laundering plan usually includes a variety of documents and procedures. Examples include Filing a Suspicious Activity Report (SAR) or a Currency Transaction Report (CTR). These reports usually take a long time to complete due to the number of details needed about an incident. Our solution can uniquely assist compliance officers in their day-to-day activities by pre-populating some fields of automated reports. A natural language generation model as your assistant, turning raw data into plain language notes.
How to maintain a Machine Learning AML Solution
So, your team has already adopted an AML machine learning solution, what happens next? There are a couple of things that are essential to ensure the smooth operation of the system. The original machine learning model might have worked well in the beginning, but it has become less effective since then. Our new feedback came from compliance officers that show that some scenarios need to be altered or updated. As with all critical systems, it is crucial to closely monitor the automated solution. Moreover, it is important to maintain it regularly and update it with the latest known money laundering practices.
Feedback from compliance officers is really important to fine-tune the system. Feedback is used to retrain the algorithm. Misplaced cases, both those
- that the system suggested as suspicious, and the compliance team investigated and confirmed as suspicious (true positives) and
- that the system suggested as suspicious, but the compliance team investigated and rejected as non-suspicious (false positives)
are fed back into the system with the appropriate label (either suspicious or not). True positives are important because the problem of money laundering is highly unbalanced. This means that there are a lot more non-suspicious cases than suspicious ones. Thus, every new suspicious case adds a lot of information to the system. False positives are important for us too. This way, we can have a sneak peek at the algorithm’s performance and diagnose the system’s “health”. By repeating these feedback steps regularly, we can guarantee a continuous improvement of the system.
Contact us to learn more on how Medoid AI can provide an automated machine learning solution on anti-money laundering to your team!
